
โลกของเทคโนโลยี AI และดาต้าเซ็นเตอร์กำลังเดินหน้าอย่างรวดเร็ว และหนึ่งในปัจจัยสำคัญที่กำหนดขีดความสามารถของระบบเหล่านี้คือ “หน่วยความจำ” ล่าสุด Rambus บริษัทผู้พัฒนาเทคโนโลยีชิปและ Silicon IP ได้ประกาศเปิดตัว HBM4E Memory Controller รุ่นใหม่ ซึ่งถูกระบุว่าเป็น คอนโทรลเลอร์ HBM ที่เร็วที่สุดในอุตสาหกรรมตอนนี้
เทคโนโลยีใหม่นี้สามารถเพิ่มความเร็วได้สูงสุดถึง 16 Gbps ต่อพิน และให้แบนด์วิดท์รวมสูงสุด 4.1 TB/s ต่อโมดูล ซึ่งเร็วกว่าคอนโทรลเลอร์ HBM4 รุ่นก่อนหน้าถึง 60% การเปิดตัวครั้งนี้ถือเป็นอีกก้าวสำคัญที่ช่วยรองรับความต้องการด้านประสิทธิภาพของ AI accelerators และ GPU รุ่นถัดไป ที่กำลังจะเข้าสู่ตลาด
เทคโนโลยี HBM4E นี้ยังถูกคาดว่าจะถูกใช้งานในชิป AI รุ่นใหม่จากบริษัทเทคโนโลยีรายใหญ่ เช่น NVIDIA Rubin Ultra GPUs และ AMD MI500 accelerators ที่กำลังพัฒนาเพื่อรองรับงาน AI และ High-Performance Computing (HPC) ในอนาคต
Rambus คือใคร และทำไมการเปิดตัวครั้งนี้ถึงสำคัญ
Rambus เป็นบริษัทด้านเทคโนโลยีที่เชี่ยวชาญเรื่อง ชิปและ Silicon IP หรือองค์ประกอบการออกแบบชิปที่ผู้ผลิตรายอื่นสามารถนำไปใช้สร้างโปรเซสเซอร์หรือระบบของตัวเองได้
บริษัทมีชื่อเสียงในด้านเทคโนโลยีที่ช่วยทำให้ การส่งข้อมูลเร็วขึ้นและปลอดภัยมากขึ้น โดยเฉพาะในระบบที่ต้องการประสิทธิภาพสูง เช่น ดาต้าเซ็นเตอร์ AI ซูเปอร์คอมพิวเตอร์ และระบบกราฟิกขั้นสูง
ในการเปิดตัวครั้งนี้ Rambus ระบุว่าบริษัทมีประสบการณ์ในการออกแบบระบบ HBM มากกว่า 100 โครงการ ซึ่งช่วยเพิ่มโอกาสให้การผลิตชิปจริงประสบความสำเร็จตั้งแต่รอบแรก หรือที่เรียกว่า first-time silicon success
สิ่งนี้มีความสำคัญอย่างมากในอุตสาหกรรมเซมิคอนดักเตอร์ เพราะการออกแบบชิปหนึ่งตัวต้องใช้ต้นทุนมหาศาล หากผลิตแล้วไม่สำเร็จตั้งแต่ครั้งแรกอาจต้องเสียเวลาปรับปรุงหลายเดือนหรือหลายปี

HBM คืออะไร ทำไมถึงสำคัญกับ AI
HBM ย่อมาจาก High Bandwidth Memory หรือหน่วยความจำที่ออกแบบมาเพื่อให้ แบนด์วิดท์สูงมาก ซึ่งหมายถึงความสามารถในการรับส่งข้อมูลจำนวนมหาศาลได้ในเวลาอันสั้น
หน่วยความจำแบบนี้ถูกใช้ในระบบที่ต้องประมวลผลข้อมูลจำนวนมาก เช่น
GPU สำหรับประมวลผลกราฟิก
AI accelerator
ซูเปอร์คอมพิวเตอร์
งาน High-Performance Computing (HPC)
ต่างจากหน่วยความจำทั่วไปอย่าง DDR ที่ติดตั้งบนเมนบอร์ด HBM จะถูกวางไว้ ใกล้กับตัวชิปประมวลผลมาก และเชื่อมต่อผ่านเทคโนโลยีการแพ็กเกจขั้นสูง เช่น 2.5D หรือ 3D packaging
ข้อดีคือ
ลดระยะทางในการส่งข้อมูล
เพิ่มความเร็วในการรับส่งข้อมูล
ลดการใช้พลังงานต่อการส่งข้อมูลหนึ่งครั้ง
ทั้งหมดนี้ทำให้ HBM กลายเป็นองค์ประกอบสำคัญของ ชิป AI รุ่นใหม่
HBM4E เร็วขึ้นอย่างไร เมื่อเทียบกับ HBM4
หนึ่งในจุดเด่นที่สุดของคอนโทรลเลอร์ใหม่จาก Rambus คือ ประสิทธิภาพที่เพิ่มขึ้นอย่างชัดเจน
ตัวเลขสำคัญมีดังนี้
คุณสมบัติHBM4HBM4Eความเร็วต่อพิน10 Gbps16 Gbpsแบนด์วิดท์ต่อโมดูล2.56 TB/s4.1 TB/sการเพิ่มประสิทธิภาพ-เร็วขึ้นประมาณ 60%
คำว่า “ต่อพิน” หมายถึงช่องทางเล็ก ๆ ที่ใช้ส่งข้อมูลระหว่างหน่วยความจำกับชิปประมวลผล ยิ่งส่งข้อมูลต่อพินได้เร็ว ระบบก็ยิ่งรับส่งข้อมูลรวมได้มากขึ้น
การเพิ่มความเร็วจาก 10 Gbps เป็น 16 Gbps ต่อพิน จึงทำให้แบนด์วิดท์รวมเพิ่มขึ้นอย่างมหาศาล
แบนด์วิดท์ระดับ 32 TB/s สำหรับ AI รุ่นถัดไป
อีกจุดที่น่าสนใจคือ เมื่อใช้ HBM4E จำนวน 8 ชิป กับ AI accelerator หนึ่งตัว จะทำให้ได้แบนด์วิดท์รวมมากกว่า 32 TB/s
ตัวเลขนี้มีความหมายมากสำหรับงาน AI เนื่องจากโมเดล AI ขนาดใหญ่ เช่น
โมเดลภาษาขนาดใหญ่ (LLM)
โมเดลสร้างภาพ
โมเดลวิดีโอ
ระบบ AI สำหรับวิทยาศาสตร์
ต้องอ่านและเขียนข้อมูลจำนวนมหาศาลอย่างต่อเนื่อง หากหน่วยความจำไม่เร็วพอ แม้ตัวชิปประมวลผลจะทรงพลังแค่ไหน ก็จะเกิดปัญหา memory bottleneck หรือคอขวดด้านหน่วยความจำ
การเพิ่มแบนด์วิดท์ระดับนี้จึงช่วยให้ AI สามารถ
ประมวลผลข้อมูลได้เร็วขึ้น
เทรนโมเดลขนาดใหญ่ได้มีประสิทธิภาพขึ้น
ลดเวลาการประมวลผล
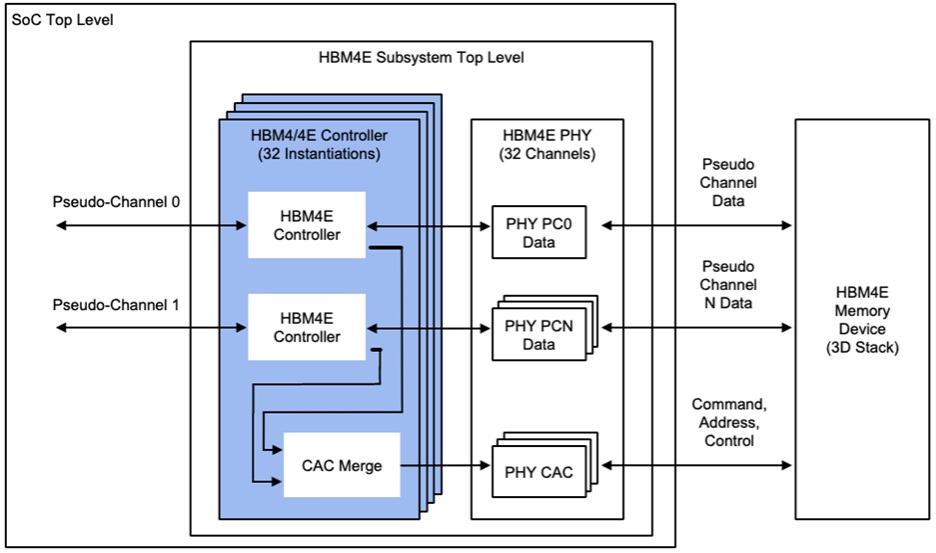
รองรับชิป AI รุ่นใหม่จาก NVIDIA และ AMD
มาตรฐาน HBM4E ที่ Rambus พัฒนาขึ้น ถูกคาดว่าจะนำไปใช้ใน GPU และ AI accelerator รุ่นถัดไปของผู้ผลิตรายใหญ่
ตัวอย่างที่ถูกกล่าวถึง ได้แก่
NVIDIA Rubin Ultra GPUs
AMD MI500 series accelerators
ชิปเหล่านี้ถูกออกแบบมาเพื่อใช้ในดาต้าเซ็นเตอร์ AI และระบบซูเปอร์คอมพิวเตอร์ ซึ่งต้องการหน่วยความจำที่เร็วมากเพื่อรองรับโมเดล AI ที่มีขนาดใหญ่ขึ้นทุกปี
ในช่วงไม่กี่ปีที่ผ่านมา ความต้องการหน่วยความจำ HBM เพิ่มขึ้นอย่างรวดเร็ว เนื่องจากบริษัทเทคโนโลยีทั่วโลกกำลังลงทุนมหาศาลใน AI infrastructure
ออกแบบให้ใช้งานร่วมกับระบบหน่วยความจำได้หลากหลาย
Rambus ระบุว่า HBM4E Controller IP สามารถทำงานร่วมกับระบบอื่น ๆ ได้อย่างยืดหยุ่น โดยสามารถจับคู่กับ
TSV PHY solutions
PHY มาตรฐานจากผู้ผลิตรายอื่น
เพื่อสร้างระบบหน่วยความจำ HBM4E แบบสมบูรณ์
เทคโนโลยีนี้สามารถนำไปใช้ในแพ็กเกจชิปแบบ
2.5D packaging
3D packaging
ซึ่งเป็นเทคนิคการประกอบชิปหลายตัวเข้าด้วยกันในระดับขั้นสูง เพื่อเพิ่มประสิทธิภาพและลดพื้นที่ของระบบ
Rambus เปิดให้บริษัทต่าง ๆ นำเทคโนโลยีไปใช้แล้ว
HBM4E Controller จาก Rambus ไม่ได้เป็นชิปสำเร็จรูป แต่เป็น IP ที่สามารถนำไปลิขสิทธิ์ใช้งาน (licensing) ได้
บริษัทผู้ผลิตชิปสามารถนำเทคโนโลยีนี้ไปใช้ในการออกแบบ
AI SoC
GPU
Custom base die
ระบบ HPC
Rambus ระบุว่าปัจจุบัน ลูกค้ากลุ่ม early access สามารถเริ่มออกแบบระบบด้วยเทคโนโลยีนี้ได้แล้ว
ทำไมการแข่งขันด้านหน่วยความจำจึงดุเดือดขึ้น
ในยุค AI ปัจจุบัน การแข่งขันไม่ได้อยู่แค่ที่พลังของ GPU หรือ CPU เท่านั้น แต่ยังรวมถึง
หน่วยความจำ
แบนด์วิดท์ข้อมูล
การเชื่อมต่อระหว่างชิป
โมเดล AI รุ่นใหม่มีขนาดใหญ่ขึ้นอย่างต่อเนื่อง บางโมเดลต้องใช้ข้อมูลระดับ หลายร้อยพันล้านพารามิเตอร์
ถ้าหน่วยความจำไม่สามารถส่งข้อมูลให้ชิปได้เร็วพอ ประสิทธิภาพของระบบทั้งหมดจะลดลงทันที
นี่จึงเป็นเหตุผลที่บริษัทเทคโนโลยีจำนวนมากกำลังลงทุนอย่างหนักกับเทคโนโลยี HBM
แนวโน้มของ HBM ในอนาคต
อุตสาหกรรมเซมิคอนดักเตอร์กำลังเดินหน้าสู่ยุคที่หน่วยความจำมีบทบาทสำคัญเทียบเท่ากับตัวโปรเซสเซอร์เอง
การพัฒนา HBM ในช่วงหลังจึงเกิดขึ้นอย่างรวดเร็ว
ลำดับวิวัฒนาการคร่าว ๆ ได้แก่
HBM2
HBM2E
HBM3
HBM3E
HBM4
HBM4E
แต่ละรุ่นเพิ่มทั้ง
ความเร็ว
ความจุ
ประสิทธิภาพพลังงาน
HBM4E จึงถูกมองว่าเป็นอีกก้าวสำคัญที่ช่วยรองรับการเติบโตของ AI infrastructure ระดับโลก
สรุปภาพรวม
การเปิดตัว HBM4E Memory Controller จาก Rambus ถือเป็นก้าวสำคัญของเทคโนโลยีหน่วยความจำสำหรับยุค AI
เทคโนโลยีนี้เพิ่มความเร็วในการส่งข้อมูลต่อพินเป็น 16 Gbps และให้แบนด์วิดท์สูงสุด 4.1 TB/s ต่อโมดูล ซึ่งเร็วกว่า HBM4 รุ่นก่อนหน้าถึง 60%
เมื่อใช้งานร่วมกับ AI accelerator ที่ติดตั้ง HBM4E หลายตัว ระบบสามารถมีแบนด์วิดท์รวมมากกว่า 32 TB/s ซึ่งช่วยรองรับงาน AI และ HPC ที่ต้องประมวลผลข้อมูลจำนวนมหาศาล
มาตรฐานนี้ยังถูกคาดว่าจะถูกใช้งานในชิป AI รุ่นใหม่จากผู้ผลิตรายใหญ่ เช่น NVIDIA และ AMD
ในโลกที่ AI เติบโตอย่างรวดเร็ว เทคโนโลยีหน่วยความจำอย่าง HBM จึงกลายเป็นหนึ่งในองค์ประกอบสำคัญที่จะกำหนดว่า ระบบ AI รุ่นต่อไปจะทรงพลังแค่ไหน





