
Google Gemma 4 บุกฝั่งเขียว! ปลดล็อกพลัง AI ระดับโลกให้รันบนการ์ดจอ NVIDIA RTX ของคุณได้แล้ว
ในวงการ AI ระดับผู้บริโภค (Consumer AI) ช่วงต้นเดือนเมษายน 2026 นี้ ไม่มีข่าวไหนจะน่าตื่นเต้นไปกว่าการที่ Google และ NVIDIA ประกาศความร่วมมือครั้งสำคัญ โดยยืนยันว่าโมเดลภาษาขนาดใหญ่ (LLM) รุ่นล่าสุดอย่าง Gemma 4 สามารถนำมาติดตั้งและใช้งาน (Deploy) บนพีซีที่ใช้การ์ดจอตระกูล NVIDIA RTX ได้อย่างสมบูรณ์แบบแล้ว
การขยับตัวครั้งนี้ตรงกับ Search Intent ของกลุ่มนักพัฒนาและสายเทคที่ต้องการ การใช้งาน AI ออฟไลน์ ที่มีความเป็นส่วนตัวสูง (Local AI) โดยไม่ต้องพึ่งพา Cloud และต้องการดึงประสิทธิภาพสูงสุดจากฮาร์ดแวร์ที่ตนเองมีอยู่
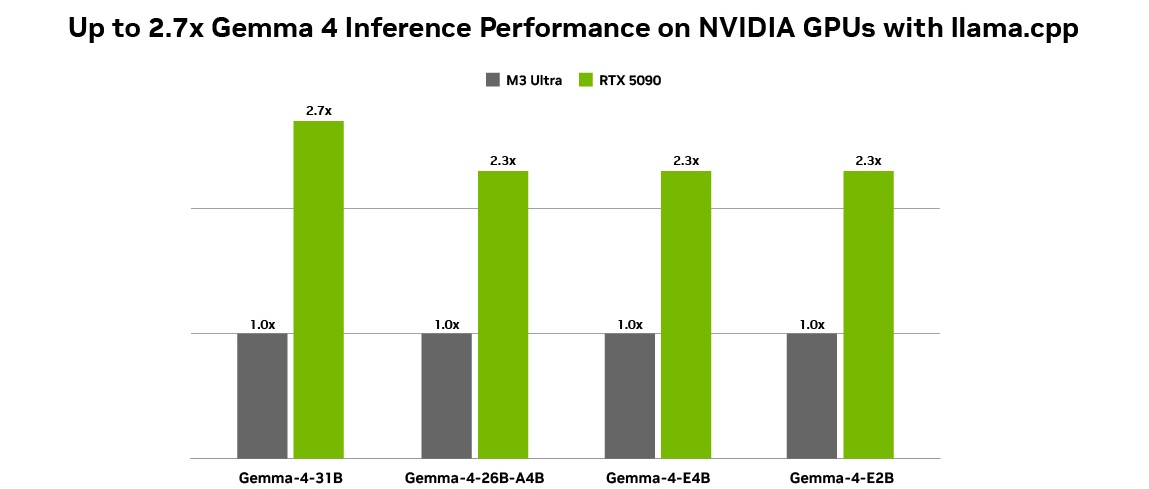
ทำไม Gemma 4 บน RTX ถึงเป็นจุดเปลี่ยนในปี 2026?
Gemma 4 คือโมเดลแบบ Open Model ที่ Google พัฒนาขึ้นโดยใช้เทคโนโลยีเดียวกับ Gemini 4.0 แต่ปรับแต่งมาให้เหมาะสมกับการรันบนอุปกรณ์พกพาและพีซี:
ความเร็วระดับแสง: ด้วยการปรับแต่งผ่าน NVIDIA TensorRT-LLM ทำให้ Gemma 4 สามารถตอบโต้ได้รวดเร็วกว่าการรันผ่าน CPU ถึง 10-15 เท่า
Privacy 100%: ข้อมูลการแชทและการประมวลผลทั้งหมดจะอยู่แค่ในเครื่องคอมพิวเตอร์ของคุณ ไม่มีการส่งกลับไปยังเซิร์ฟเวอร์ของ Google
การทำงานร่วมกับ ChatRTX: NVIDIA ได้อัปเดตแอปพลิเคชัน ChatRTX ให้รองรับ Gemma 4 ทันที ทำให้ผู้ใช้ทั่วไปสามารถ "คุยกับไฟล์ในเครื่อง" (RAG) ได้อย่างแม่นยำขึ้นกว่ารุ่นก่อนหน้าอย่างเห็นได้ชัด
วิธีเริ่มต้นใช้งาน Gemma 4 บนเครื่องของคุณ
หากคุณมีการ์ดจอ RTX อยู่แล้ว สามารถเลือกใช้งานได้ 2 ช่องทางหลัก:
สำหรับผู้ใช้ทั่วไป: ดาวน์โหลดแอป NVIDIA ChatRTX เวอร์ชันล่าสุด แล้วเลือกโมเดล Gemma 4 จากเมนู Dropdown ระบบจะทำการดาวน์โหลดและตั้งค่าให้โดยอัตโนมัติ
สำหรับนักพัฒนา: สามารถโหลดโมเดลจาก Hugging Face และใช้งานผ่านเฟรมเวิร์กอย่าง Ollama หรือ LM Studio ที่มีการอัปเดตให้รองรับสถาปัตยกรรมใหม่ของ Gemma 4 เรียบร้อยแล้ว
บทสรุป: ยุคแห่ง Local AI ได้มาถึงแล้ว
การที่โมเดลระดับเรือธงของ Google อย่าง Gemma 4 สามารถรันได้บนคอมพิวเตอร์บ้านในปี 2026 แสดงให้เห็นว่าช่องว่างระหว่าง Cloud AI และ Local AI กำลังแคบลงเรื่อย ๆ สำหรับคอนเทนต์ครีเอเตอร์หรือนักพัฒนา การมี AI ที่เก่งระดับโลกอยู่บนการ์ดจอตัวเองจะช่วยประหยัดทั้งเวลาและเพิ่มความปลอดภัยในการทำงานได้อย่างมหาศาลครับ
ที่มา wccftech





